7. Computación en la nube
La computación en la nube se ha convertido en la manera más habitual de gestionar los diferentes recursos necesarios para una aplicación web.
Importante
Las habilidades que deberías adquirir con este tema incluyen las siguientes:
Entender la diferencia entre los distintos niveles de abstracción proporcionados por los diferentes modelos de computación en la nube.
Conocer, saber usar y relacionar entre ellos varios de los servicios de infraestructura y plataforma disponibles en la nube.
Saber implantar en Google App Engine aplicaciones web escritas en Node.js que usen las bases de datos relacionales de Google Cloud SQL.
7.1. Configuración del entorno de trabajo para Google Cloud Platform
En las actividades de este tema vamos a usar diversos servicios de Google Cloud Platform. Aunque plataformas como Amazon Web Services, Microsoft Azure, IBM Cloud, Rackspace o Google Cloud Platform suelen ofrecer de forma gratuita un acceso limitado a algunos de sus servicios, en esta asignatura vas a crear un proyecto en Google Cloud Platform y asignarlo a una cuenta de facturación especial para centros educativos que Google ofrece a los estudiantes de la universidad. Para recibir los créditos educativos, tendrás que usar la cuenta que la universidad te asigna con dominio gcloud.ua.es; asegúrate de que la tienes activada antes de seguir leyendo.
Importante
Ten en cuenta que en ningún momento has de dar de indicar los datos de ninguna tarjeta de crédito o cuenta bancaria. Si el sistema te pide algo así, es que estás haciendo algo mal.
En las semanas anteriores al estudio de este tema, el profesor compartirá contigo a través de un anuncio en UACloud u otro medio similar un enlace a una página web donde podrás solicitar los créditos educativos. En dicha página, tendrás que indicar tu dirección de correo electrónico de gcloud.ua.es y tu nombre. Una vez que hayas enviado el formulario, recibirás un mensaje de confirmación por correo electrónico con un enlace para activar tu cuenta de Google Cloud Platform. Solo se puede obtener un cupón por estudiante. Para comprobar que todo ha ido bien, basta con que accedas al servicio de facturación y compruebes que tienes una cuenta con unos $50 a tu disposición.
Hazlo tú ahora
Sigue las instrucciones que vienen a continuación para configurar tu entorno de trabajo para las actividades de este tema.
Comienza instalando Node.js y SQLite como se estudió en el tema anterior en la sección «Configuración del entorno de trabajo para ejecutar localmente una aplicación web». También necesitarás tener instalado gcloud, un cliente de línea de órdenes (CLI) que permite interactuar con Google Cloud Platform desde la línea de órdenes.
Importante
El fichero dai-bundle-dev que se menciona al comienzo del apartado «Configuración del entorno de trabajo para ejecutar localmente una aplicación web» del capítulo anterior también te permite instalar el CLI de Google Cloud. Edita el script install.sh y cambia, si procede, el valor de las variables de entorno del comienzo para que se instale.
Las instrucciones de instalación del CLI cambian de un sistema operativo a otro; para el caso de Linux, y sin necesidad de tener privilegios de administrador, puedes ejecutar lo que sigue; sáltate este paso si has instalado el SDK con el script mencionado antes:
curl https://sdk.cloud.google.com | bash
Ahora cierra el terminal actual y abre uno nuevo para que se actualicen los valores de las variables de entorno. Una vez instalado, has de vincular el SDK con tu cuenta de Google Cloud Platform (en este caso, tu cuenta gcloud.ua.es):
gcloud init
Si posteriormente el sistema CLI se desvinculara por algún motivo de tu cuenta, puedes volver a emparejarlo haciendo:
gcloud auth login
Ahora tienes que ejecutar este script de Linux para crear un proyecto, vincularlo a tu cuenta y añadir al profesor como administrador. Antes de ejecutarlo edítalo y pon tu cuenta completa de gcloud en la variable ESTUDIANTE y la cuenta que el profesor te habrá indicado previamente en la variable PROFESOR. Es posible que la ejecución del script se demore por unos minutos.
Importante
El script está preparado en principio para Linux. Puedes adaptarlo fácilmente para otros sistemas operativos. Otra opción es abrir el fichero correspondiente e ir copiando una a una sus instrucciones en el terminal.
Ahora deberías poder ver los proyectos que tienes creados en Google Cloud Platform con:
gcloud projects list
Y para ver cuál es el proyecto por defecto:
gcloud config get-value project
Lo más habitual es que solo tengas el proyecto de la asignatura, cuyo nombre comienza por dai, pero si el proyecto seleccionado por defecto es uno diferente (quizás un proyecto que hayas creado tú por tu cuenta) puedes cambiarlo haciendo:
gcloud config set project <id>
donde <id> sería el id del proyecto obtenido de la lista proporcionada por gcloud projects list.
Importante
Para no generar gastos innecesarios, recuerda eliminar los recursos que hayas creado y que no vayas a seguir utilizando, cuando acabes una sesión de trabajo con Google Cloud Platform. Establece ahora una alarma de gasto en tu cuenta de facturación de Google Cloud Platform.
7.2. Caso de uso: integración de servicios de Google Cloud Platform
En esta actividad vas a crear una solución que integre diversos servicios de Google Cloud Platform. Ve unos vídeos, explora los documentos de introducción enlazados y, a continuación realiza el ejercicio propuesto.
Hazlo tú ahora
Ve los vídeos de la lista de reproducción de introducción a Google Cloud Platform y toma nota de las principales ideas allí expuestas. Los vídeos tienen los subtítulos correctos en inglés y puedes leerlos en otros idiomas mediante traducción automática (lo que implica que habrá errores con cierta frecuencia). Ten en cuenta que la duración total de todos los vídeos de la lista es de alrededor de 40 minutos.
Para conseguir llevar a cabo la siguiente tarea, necesitarás leerte y practicar con estas guías rápidas (de nuevo la versión recomendada es la original en inglés, pero puedes cambiar el idioma al final de la página):
Creación de una máquina virtual con Linux en Compute Engine.
Ejecutar un servidor Apache básico en Compute Engine.
Subir ficheros a Cloud Storage. Puede que el tutorial no lo mencione, pero para poder hacer públicos objetos puntuales de un bucket, tendrás que editar las opciones de acceso al bucket y cambiarlas a fine-grained.
Implementar una aplicación sencilla en Node.js en App Engine.
Crear una función en Cloud Functions.
Crear una función desde la línea de órdenes en Cloud Functions.
Hazlo tú ahora
Lanza en una estancia de Google Compute Engine un servidor web escrito en Node.js con Express (esto se estudió en el tema anterior) que sirva una página web sencilla y ofrezca un servicio GET que realice una tarea simple, como por ejemplo, invertir una cadena de texto. La página web ha de invocar mediante la API Fetch al servicio web y, además, contener una imagen que previamente habrás subido a Google Cloud Storage. Añade a continuación en Google Cloud Functions una función en JavaScript que devuelva la cadena recibida como parámetro con las vocales eliminadas e invoca también este servicio desde la página web; recuerda que, dado que la invocación del servicio se hará desde una página web descargada desde un servidor diferente, tendrás que añadir res.header("Access-Control-Allow-Origin","*") a tu función para cumplir con el estándar CORS. Para simplificar, usa la consola web de Google Cloud Platform siempre que te sea posible. ¡Elimina todos los recursos reservados cuando acabes!
7.3. Una definición de computación en la nube
Después de la toma de contacto de la actividad anterior, estamos en disposición de poder caracterizar de forma más precisa a qué nos referimos con la computación en la nube.
Hazlo tú ahora
Lee detenidamente la definición de computación en la nube dada por el National Institute of Standards and Technology en el documento «The NIST Definition of Cloud Computing» y asegúrate de que entiendes cuáles son las características fundamentales de la computación en la nube, así como los diferentes modelos de servicios e implantación existentes. Lee con calma el documento ya que tiene una gran densidad terminológica y conceptual.
Por elegir algún momento, podemos establecer el inicio de la computación en la nube en 2006 cuando Amazon lanza Amazon Web Services para explotar comercialmente la tecnología que había desarrollado para su propio portal. Comienza entonces una transición desde el hosting tradicional (en el que uno compraba o alquilaba una cantidad determinada de recursos) a la computación en la nube (en la que los servicios y recursos computacionales son escalables, se ofrecen bajo demanda y se facturan, como el agua o la luz, en base al consumo real realizado).
Algunas de las principales características de la computación en la nube son:
Existencia de un pool de recursos computacionales disponible para todos los clientes.
Virtualización a todos los niveles para maximizar la utilización del hardware.
Escalado elástico (en ambos sentidos) e inmediato según las necesidades.
Se paga por lo que se usa (por horas, minutos, GBs o MBs, por ejemplo).
Reducción para el cliente de gastos de capital (CAPEX), pero en ocasiones también de gastos operativos (OPEX).
Acceso automático vía APIs web o SDKs a todos los servicios.
La siguiente gráfica muestra cómo con la computación en la nube los gastos se ajustan en cada momento a la demanda a diferencia de lo que ocurría con el hosting tradicional:
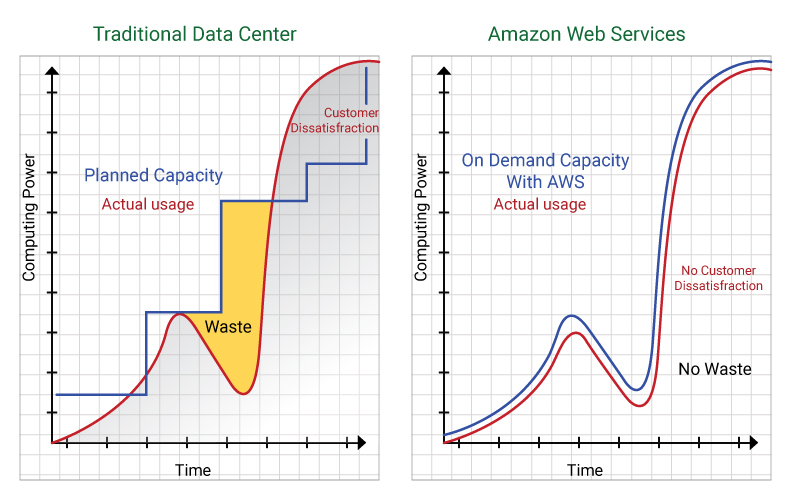
Comparación entre el coste con un servicio de hosting tradicional y con la computación en la nube.
Nota
Para crear una nube privada, es decir, un sistema con hardware propio pero con el que se interactúa como con una nube pública, existen varios sistemas de código abierto como OpenStack, CloudStack, Cloud Foundry u OpenShift (los dos primeros como infrastructure as a service y los dos últimos como platform as a service).
Hazlo tú ahora
Ve los dos primeros vídeos de la lista de reproducción de centros de datos para computación en la nube y toma nota de las principales ideas allí expuestas. Todos los vídeos tienen subtítulos bien transcritos como mínimo en inglés. Puedes leerlos en otros idiomas mediante traducción automática (lo que implica que habrá errores con cierta frecuencia). Ten en cuenta que la duración total de los dos primeros vídeos de la lista es de alrededor de 45 minutos.
7.4. Publicación avanzada de la aplicación del carrito en Google App Engine integrada con Google Cloud SQL
Vamos a ver cómo desplegar la aplicación del carrito del tema anterior en Google App Engine, el servicio de plataforma de aplicaciones de Google Cloud Platform, de manera que esta vez los datos tengan auténtica persistencia. Dado que las máquinas virtuales que se asignen a nuestra aplicación de Google App Engine pueden ser eliminadas o creadas en cualquier momento en base a la demanda, necesitamos almacenar los datos que maneje la aplicación en una base de datos alojada en otro lugar: Google Cloud Platform cuenta con Google Cloud SQL, un servicio de bases de datos relacionales en la nube que incluye el gestor MySQL. En el tema anterior vimos que la aplicación del carrito ya estaba configurada para trabajar con MySQL a través de Knex.js, por lo que no es necesario modificar el código. Al comienzo de este tema, en el apartado «Configuración del entorno de trabajo para Google Cloud Platform», también se explica cómo configurar el cliente de línea de órdenes gcloud. Para que la aplicación pueda usar MySQL debemos crear y configurar una instancia de máquina virtual para la base de datos en Google Cloud SQL.
Hazlo tú ahora
Sigue las instrucciones que vienen a continuación para aprender cómo desplegar una aplicación como la del carrito en Google App Engine.
Para crear la instancia de Cloud SQL desde el terminal es necesario ejecutar desde la línea de órdenes:
gcloud sql instances create <instancia> --tier=db-f1-micro --region=europe-west3 --root-password=<contraseñaAdmin> --database-version=MYSQL_8_0
donde <instancia> es el nombre la instancia de base de datos y <contraseñaAdmin> la contraseña que queremos para el administrador de la instancia.
La primera vez que ejecutes la línea anterior, obtendrás un mensaje informando de que la API de SQL no está activada y ofreciéndote la opción de activarla; pídele que la active. Es posible que también se te solicite aceptar las condiciones del servicio. Muchos servicios de Google Cloud Platform están desactivados inicialmente para evitar que las aplicaciones utilicen servicios de pago que no han sido autorizados explícitamente.
Nota
La creación de la instancia de la base de datos puede tardar varios minutos. No sigas con este tutorial hasta que no se confirme su creación. En algunos casos puede llegar hasta unos 15 minutos, así que puedes aprovechar para hacer otra cosa mientras.
Ahora vamos a crear un nuevo usuario alternativo al administrador para acceder a la base de datos. Para ello ejecutamos:
gcloud sql users create <usuario> --host=% --instance=<instancia> --password=<contraseña>
Nota
Recuerda que todas las acciones que estamos ejecutando desde el terminal también podrían llevarse a cabo manualmente desde la consola web de Google Cloud Platform. De esta manera, sin embargo, no son automatizables. Por ejemplo, para crear un usuario alternativo para la bases de datos como acabamos de hacer, también podríamos ir a la consola web de administración de instancias de bases de datos, seleccionar la instancia creada anteriormente, y desde la pestaña Usuarios crear una cuenta de usuario que pueda conectarse desde cualquier host.
A veces hay sutiles diferencias entre ambos enfoques. Por ejemplo, para versiones de MySQL anteriores a la 8, a los usuarios creados desde la línea de órdenes había que concederles mediante GRANT permisos adicionales.
A continuación, creemos una base de datos en la instancia de Cloud SQL para nuestra aplicación:
gcloud sql databases create <bd> --instance=<instancia>
donde <bd> es el nombre de la base de datos e <instancia> es el nombre de la instancia de Cloud SQL que creamos anteriormente.
Para comprobar que usuario y base de datos han sido creados correctamente, podemos consultar los usuarios y las bases de datos existentes haciendo:
gcloud sql users list --instance=<instancia>
gcloud sql databases list --instance=<instancia>
Ahora necesitamos conocer el nombre de conexión de la instancia que aparece en el campo connectionName al ejecutar:
gcloud sql instances describe <instancia>
En Linux puedes mostrar solo la línea que contiene el nombre de conexión con:
gcloud sql instances describe <instancia> | grep connectionName
Ahora, añade los datos anteriores a un fichero llamado .env que estará en la misma carpeta que config.js y app.js de la aplicación del carrito:
1GCP_SQL_USER=<usuario>
2GCP_SQL_PASSWORD=<contraseña>
3GCP_SQL_DATABASE=<bd>
4GCP_SQL_INSTANCE_CONNECTION_NAME=/cloudsql/<connectionName>
Observa que el nombre de la conexión va precedido de /cloudsql en la última variable de entorno.
El fichero app.yaml contiene información para Google App Engine como, entre otras cosas, las variables de entorno que se inicializarán antes de arrancar la aplicación. A diferencia de Heroku, estas variables de entorno no pueden definirse por medio del cliente de línea de órdenes (gcloud) sino únicamente a través de este fichero.
Para subir el código de la aplicación a Google App Engine y abrirla en el navegador basta con hacer:
gcloud app deploy
Nota
Un proyecto de Google Cloud Platform solo puede tener una aplicación de App Engine asociada como máximo. El proyecto que el profesor ha creado para ti ya tiene una aplicación de App Engine asociada; para otros proyectos sin aplicación vinculada, la línea anterior podría mostrar un mensaje ofreciendo crearla en ese momento.
La aplicación ya está desplegada en la nube. Podemos ahora abrirla directamente en el navegador sin necesidad de consultar su URL haciendo:
gcloud app browse
Para ver todos los mensajes de log emitidos por la aplicación:
gcloud app logs read
Y para ir viéndolos en un terminal mientras se van generando:
gcloud app logs tail
En la consola web los logs se muestran dentro de las opciones de Logging en el bloque Operations.
Importante
Las instancias de Cloud SQL tienen un coste relativamente alto, por lo que tenemos que hacer un uso moderado de ellas para no agotar los créditos disponibles. En primer lugar, asegúrate de que, como se dice más arriba, indicas el tipo de instancia de base de datos db-f1-micro (el más barato) y ningún otro al crear la instancia. Además, acostúmbrate a dormir tu instancia de base de datos cuando no vayas a trabajar en las siguientes horas con ella (no es necesario que lo hagas constantemente mientras estás desarrollando, pero sí cuando vayas a dejar de hacerlo) ejecutando:
gcloud sql instances patch <instancia> --activation-policy never
Para despertar posteriormente la instancia puedes ejecutar:
gcloud sql instances patch <instancia> --activation-policy always
Es posible que de vez en cuando el profesor ejecute un script que intente mandar a dormir todas las instancias de base de datos por si hay estudiantes que han olvidado hacerlo. Despierta tu instancia si inesperadamente comienzas a recibir errores al acceder a la base de datos, porque lamentablemente con la segunda generación de instancias de MySQL de Google Cloud SQL esto no ocurre automáticamente. Evidentemente, en una aplicación real la base de datos ha de estar siempre disponible o establecerse un procedimiento automático que la despierte, pero para los propósitos de la asignatura y de cara a ahorrar costes, dormir y despertar la instancia de base de datos es razonablemente admisible.
Para poder ejecutar instrucciones de SQL sobre la base de datos y asegurarnos de que nuestro programa está rellenándola correctamente, es necesario ir a la consola web de Google Cloud Platform, abrir el terminal web Cloud Shell y hacer:
gcloud sql connect <instancia> --user=<usuario>
Desde el terminal web podemos seleccionar nuestra base de datos con use <bd>;, donde <bd> es el nombre correspondiente, y ejecutar instrucciones SQL como select * from productos;.
Nota
La orden anterior de gcloud para conectarte a la base de datos también se puede lanzar desde un terminal local, pero es necesario que el sistema tenga MySQL instalado. También se pueden usar clientes de MySQL como Adminer o phpMyAdmin. Si se desea usar la base de datos de Cloud SQL mientras se desarrolla en modo local se puede hacer con Cloud SQL Proxy; en este curso, sin embargo, no será necesario porque nuestras aplicaciones usarán SQLite en modo local y MySQL solo cuando se implanten en la nube.
7.5. Ejecución de contenedores en la nube
Docker es una plataforma que nos permite desplegar contenedores, que incluyen aplicaciones completas y sus dependencias a todos los niveles (sistema operativo, entornos de ejecución, librerías, programas adicionales, ficheros de configuración, etc.). Los contenedores son instancias de una imagen. Cada imagen se define mediante un fichero de texto usualmente denominado Dockerfile.
Hazlo tú ahora
Lee la página de introducción a Docker. Después, lee el tutorial sobre cómo lanzar un contenedor y configurar un contenedor para una aplicación web basada en Node.js.
En esta actividad vamos a ver cómo crear una imagen de nuestra aplicación del carrito y lanzar contenedores basados en ellas. Ambas acciones las realizaremos tanto localmente (para ello necesitas tener instalado docker en tu ordenador) como en Google Cloud Platform. A diferencia del Dockerfile del tutorial anterior, no nos basaremos en una imagen del registro que ya contiene Node.js (según se indicaba en la orden FROM), sino que, para mostrar un ejemplo más general, nuestra imagen se basará en una imagen de Ubuntu.
Para instalar Docker en Ubuntu se puede hacer:
sudo apt install docker.io
sudo groupadd docker
sudo gpasswd -a $USER docker
newgrp docker
Las tres últimas líneas son para poder ejecutar docker sin permisos explícitos de administrador, aunque, en cualquier caso, la aplicación se ejecutará con estos permisos; alternativas de código abierto como Podman permiten ejecutar contenedores sin estos privilegios; en ese caso, basta con instalar los paquetes podman y podman-docker.
Los dos ficheros relevantes de la aplicación del carrito para este apartado son .dockerignore (especifica qué ficheros o directorios ignorar en instrucciones como COPY) y, principalmente, Dockerfile, cuyo contenido es el siguiente:
1FROM ubuntu:24.04
2
3ARG DEBIAN_FRONTEND=noninteractive
4RUN apt update \
5 && apt install -y npm nodejs sqlite3 \
6 && rm -rf /var/lib/apt/lists/*
7
8RUN mkdir /app
9WORKDIR /app
10
11COPY "package.json" .
12
13RUN npm install
14
15COPY . .
16
17EXPOSE 5000
18
19CMD ["node","app.js"]
Los pasos para crear una imagen y lanzar un contenedor local desde la línea de órdenes son:
docker build --tag imagen-carrito .
docker images
docker run --detach --publish 8001:5000 --name contenedor-carrito imagen-carrito
docker ps --all
Podemos ahora probar nuestra aplicación en localhost:8001. Las siguientes instrucciones detienen el contenedor, vuelven a lanzarlo, ejecutan una sesión del shell dentro de él, lo vuelven a detener y, finalmente, lo eliminan:
docker stop contenedor-carrito
docker start contenedor-carrito
docker exec --interactive --tty contenedor-carrito bash
docker stop contenedor-carrito
docker rm contenedor-carrito
Un uso habitual de Docker es el de tener contenedores con todo el software necesario para programar una aplicación de forma que nos aseguremos que todos los miembros del equipo tengan exactamente el mismo entorno de desarrollo. En ese caso, es muy ineficiente tener que volver a crear la imagen ante cada cambio en el código que queramos probar. Otro enfoque también ineficiente pasa por editar los ficheros dentro del contenedor, pero en ese caso para hacer esos cambios persistentes, tendríamos que usar ciertas instrucciones que crean una nueva imagen a partir del estado de un contenedor. Una solución mucho mejor es usar volúmenes, que nos permiten enlazar ciertos directorios del contenedor con directorios externos:
docker run --detach --publish 8001:5000 --volume "$PWD":/app --name contenedor-carrito imagen-carrito
Si editamos el contenido de public/carrito.html veremos cómo la aplicación web se actualiza inmediatamente. Cuando tengamos la aplicación lista, podemos crear la imagen copiando, esta vez sí, el contenido local al sistema de ficheros del contenedor. Para terminar, podemos eliminar el contenedor e incluso la imagen:
docker stop contenedor-carrito
docker rm contenedor-carrito
docker rmi imagen-carrito
Podemos repetir los pasos anteriores (sin necesidad de tener Docker instalado) usando servicios en la nube. En el caso de GCP, la generación de la imagen y su subida a un registro se puede hacer con Cloud Build, mientras que para el lanzamiento del contenedor podemos usar Cloud Run.
En lo siguiente se asume que la variable PROYECTO contiene el identificador del proyecto actual. Recuerda que para obtener el proyecto actual o cambiarlo, si es necesario, puedes hacer:
gcloud config get-value project
gcloud config set project $PROYECTO
Los pasos siguientes crean un repositorio para imágenes de Docker (dado que se pueden almacenar otros tipos de objetos, en GCP lo llaman repositorio de artefactos), construye una imagen a partir del Dockerfile y el contenido del directorio actual y, finalmente, la ejecuta:
gcloud artifacts repositories create repositorio-docker --repository-format=docker --location europe-west3
gcloud artifacts repositories list
gcloud builds submit --tag europe-west3-docker.pkg.dev/$PROYECTO/repositorio-docker/imagen-carrito:v1
gcloud artifacts docker images list europe-west3-docker.pkg.dev/$PROYECTO/repositorio-docker
gcloud run deploy servicio-carrito --image europe-west3-docker.pkg.dev/$PROYECTO/repositorio-docker/imagen-carrito:v1 --platform managed --region europe-west3
A la pregunta de si permitir invocaciones no autorizadas en la última orden contestamos que sí. La ejecución de la última orden nos dará el URL donde probar la aplicación. Desde la consola web podemos acceder al Artifact Registry y a Cloud Build para ver el repositorio con la imagen y el contenedor, respectivamente. Para eliminar el contenedor y el repositorio completo:
gcloud run services delete servicio-carrito --region europe-west3
gcloud artifacts repositories delete repositorio-docker --location europe-west3
Cloud Run, a diferencia de App Engine, no mantiene la instancia ejecutando continuamente o durante unos minutos después de la última solicitud, por lo que su coste es inferior.